SLS Lecture 11 : Program Anatomy II : Functions
Contents
11. SLS Lecture 11 : Program Anatomy II : Functions#
create a directory
mkdir sum; cd sumcopy sumit and usesumit code examples
add a
Makefileto automate assembling and linkingwe are going run the commands by hand this time to highlight the details
add our
setup.gdbandusesumABC.gdbto make working in gdb easiernormally you would want to track everything in git
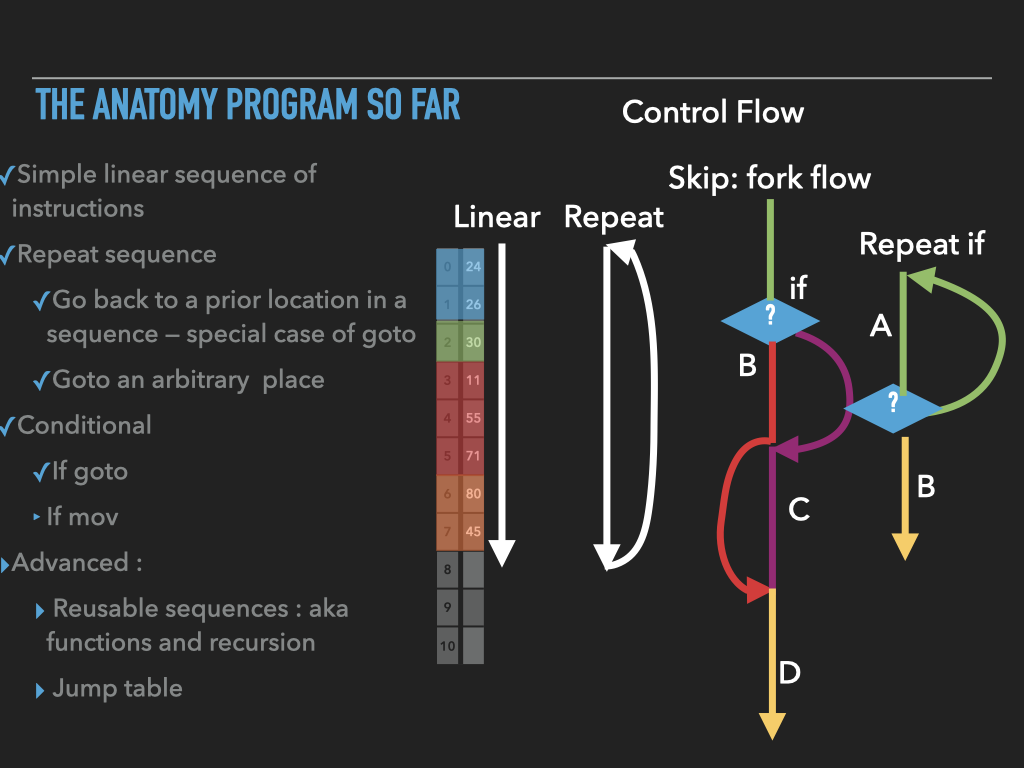






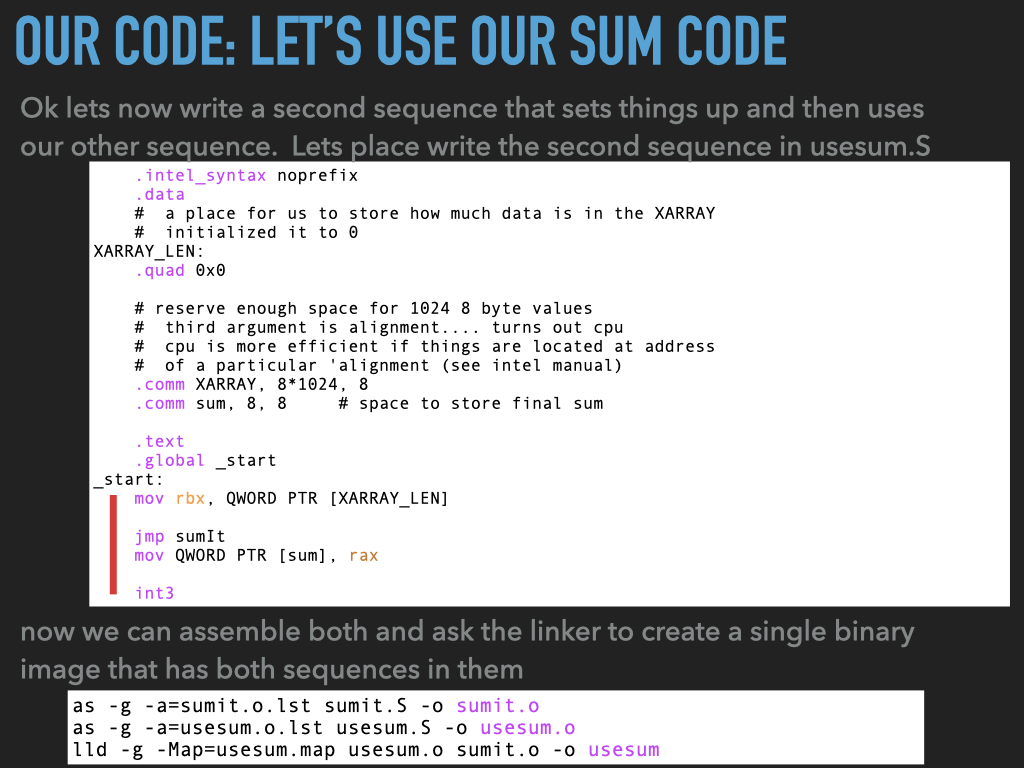

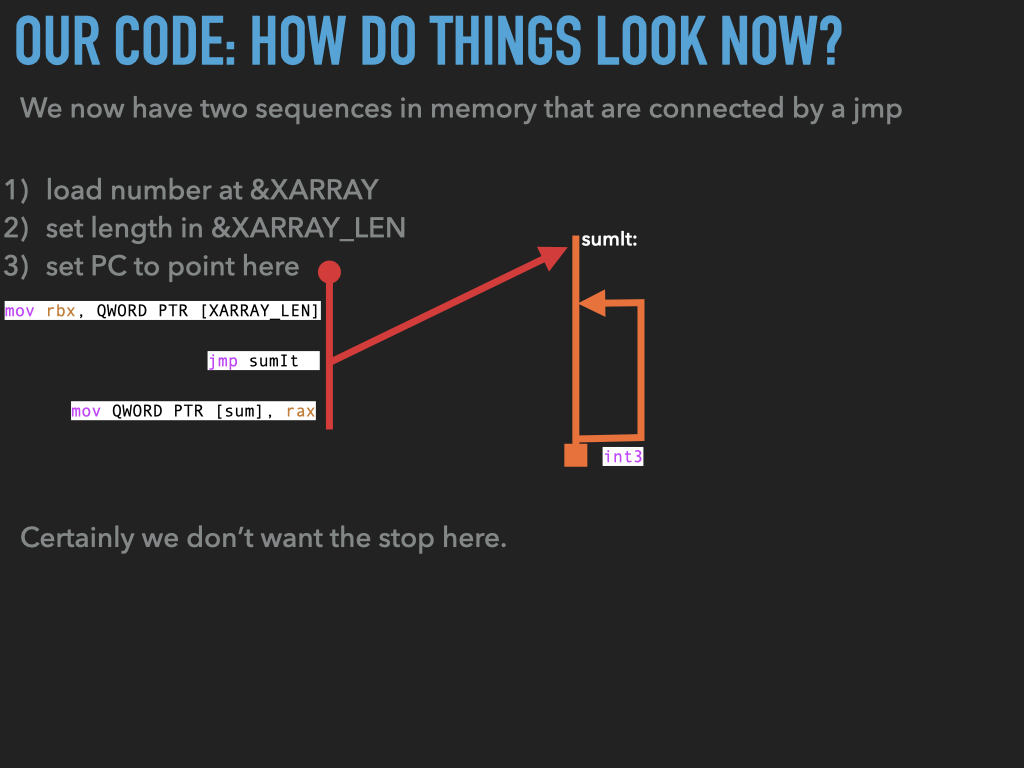
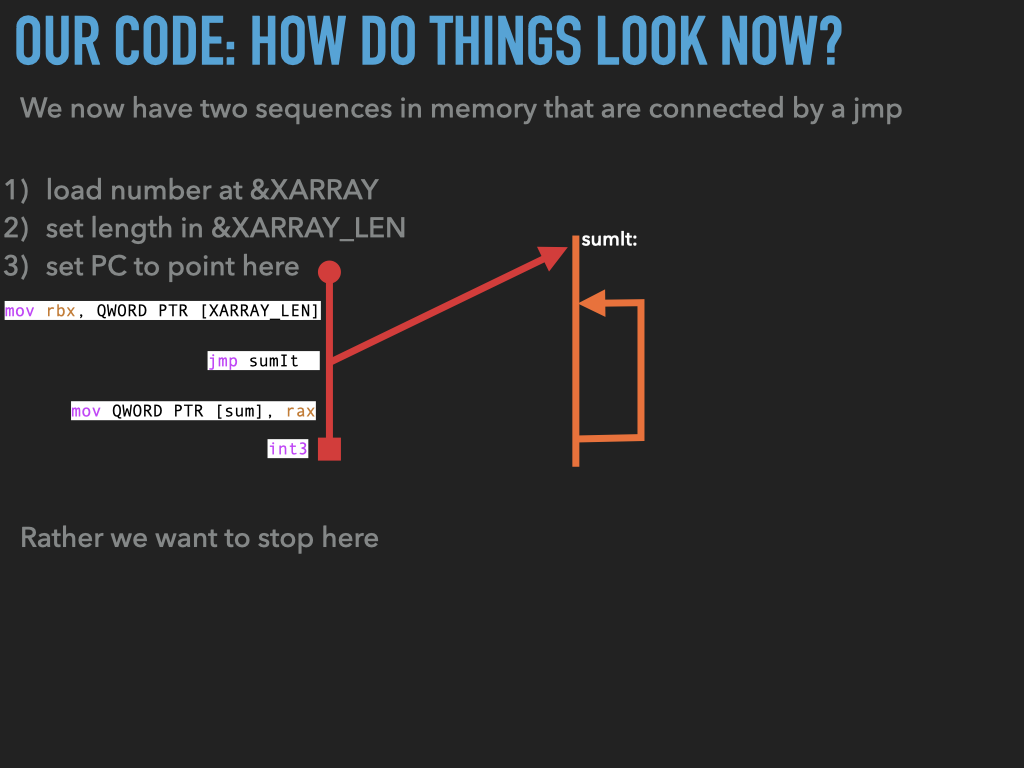









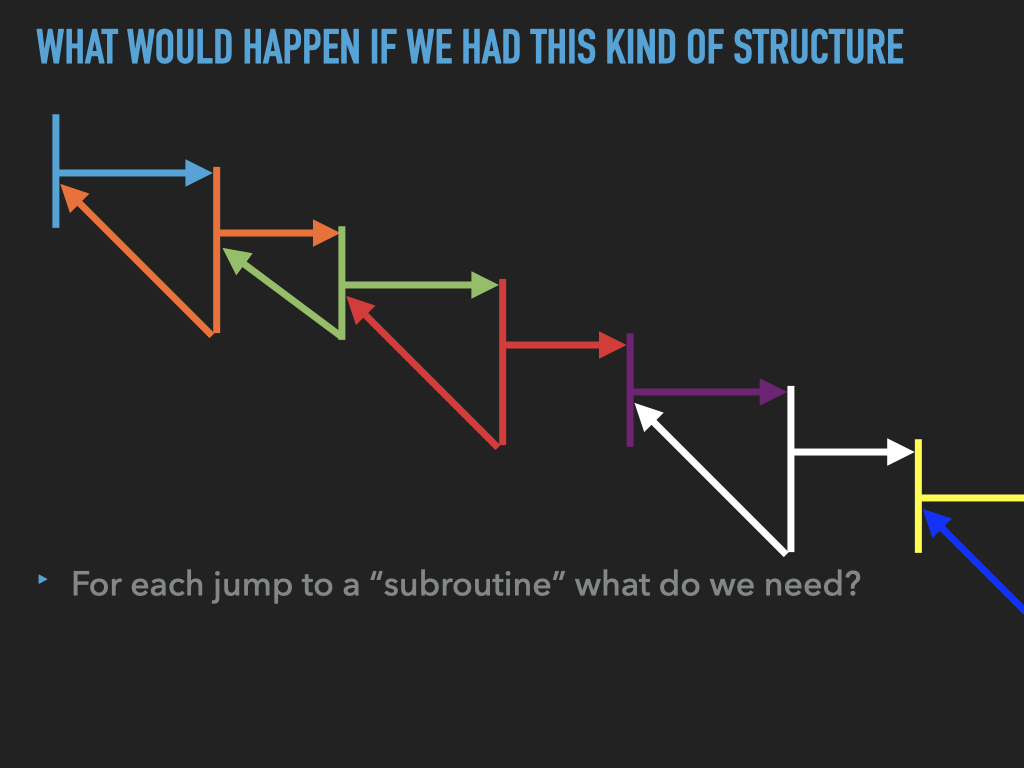
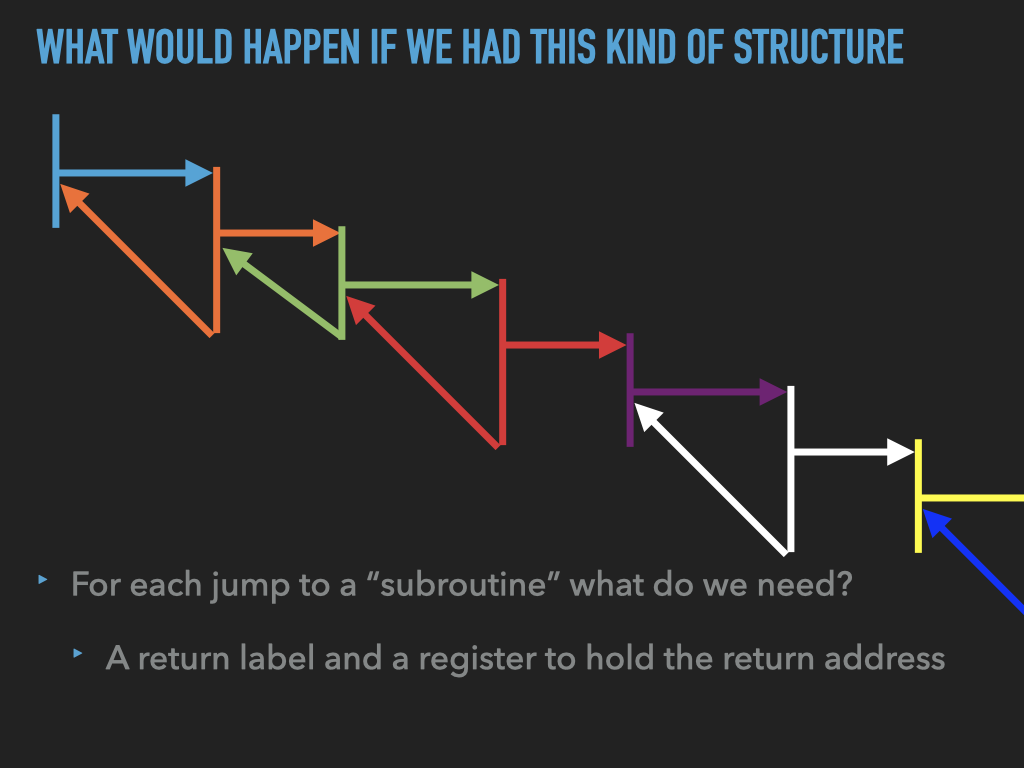

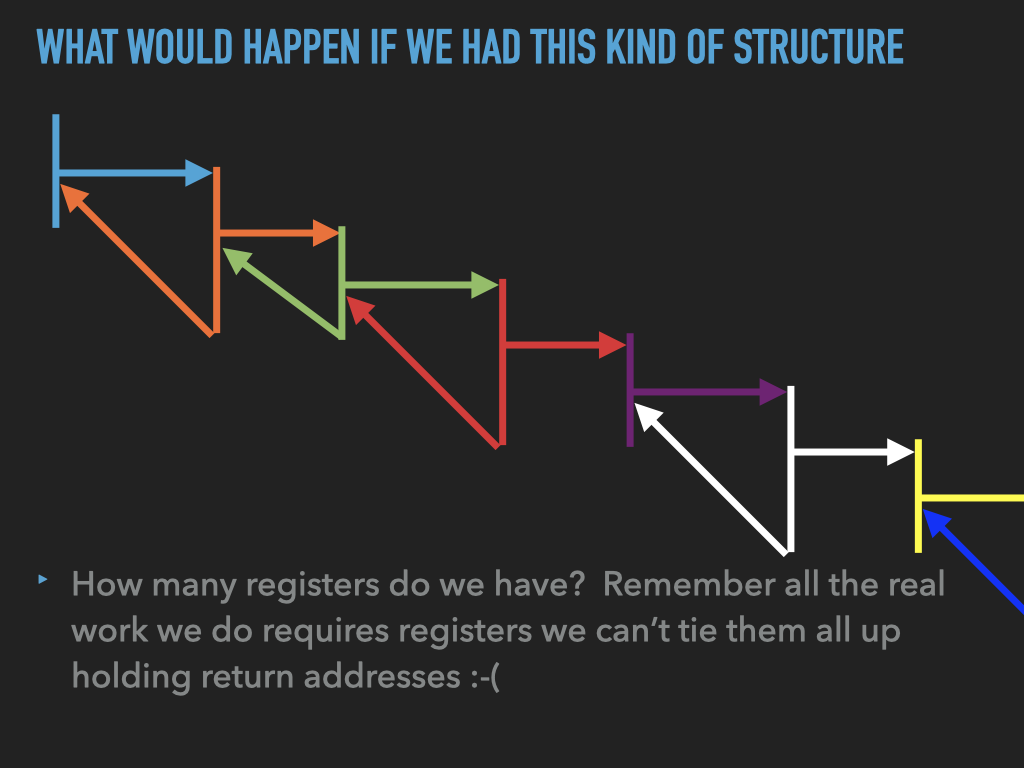












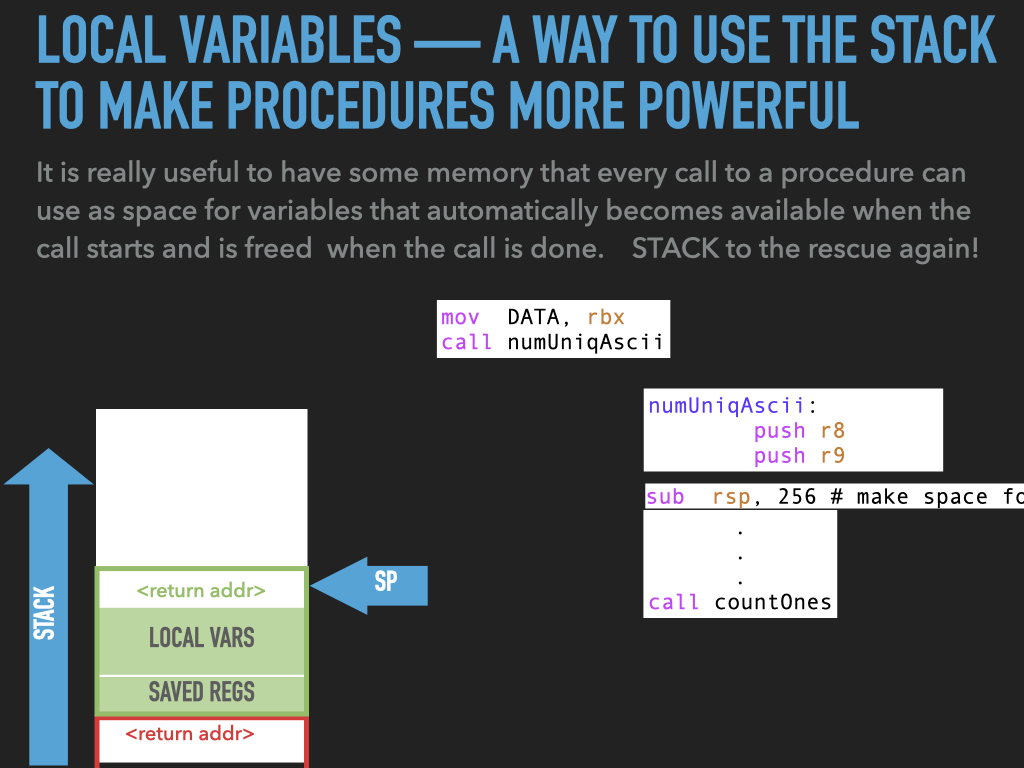
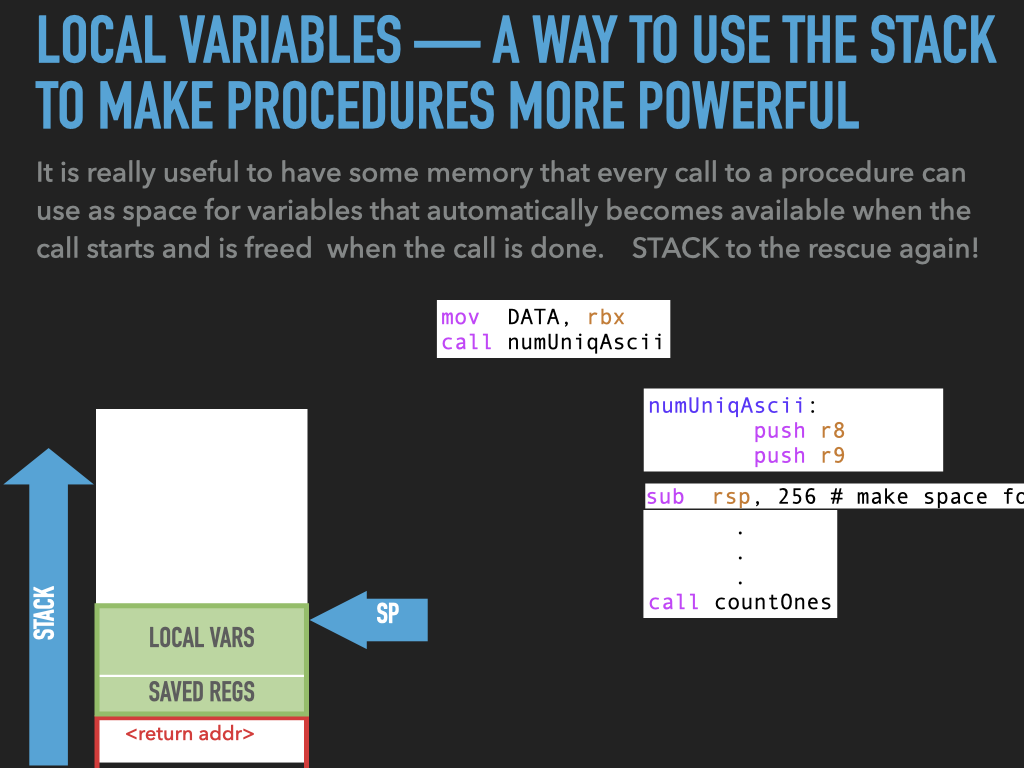
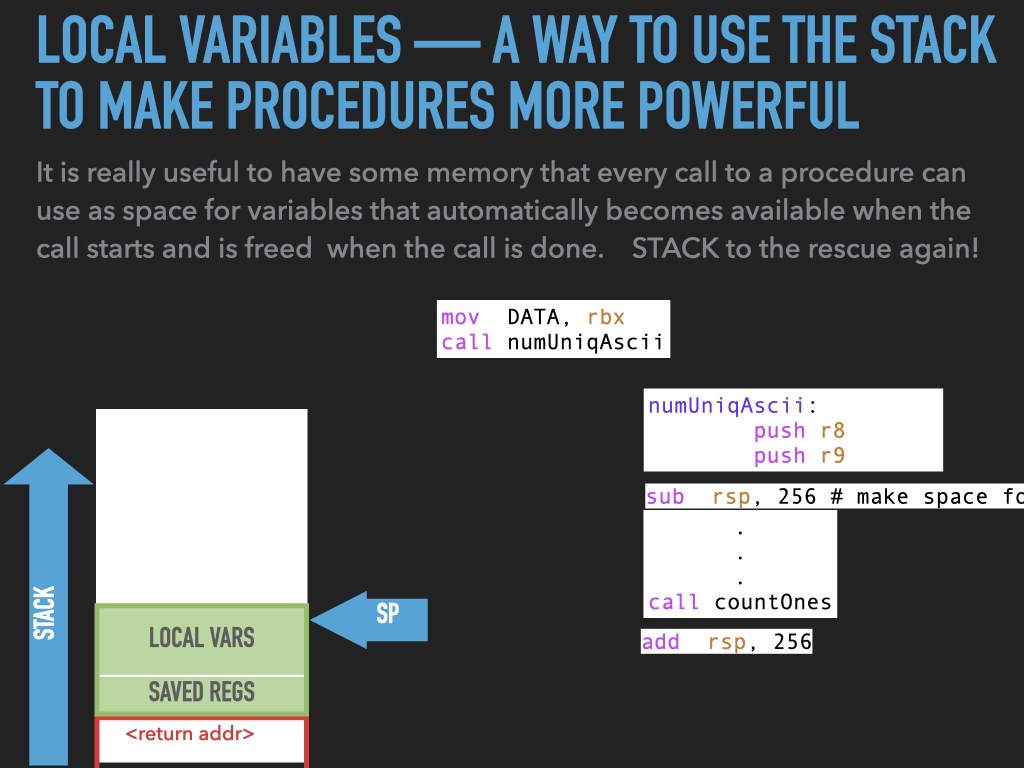

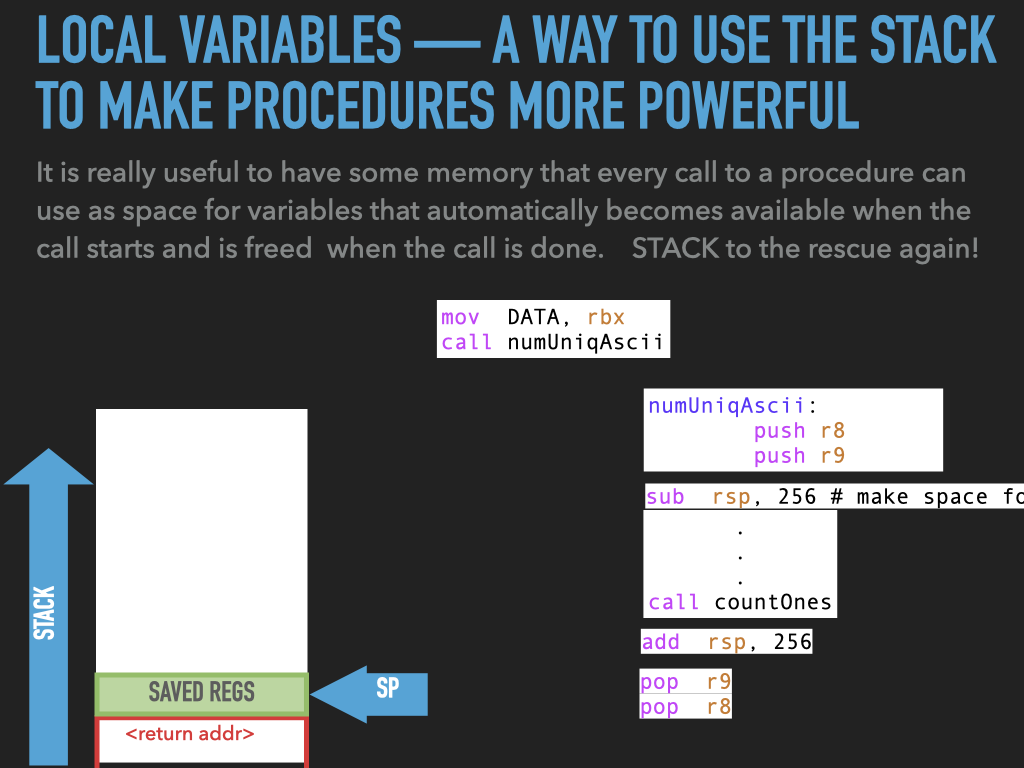




11.1. Examples used in previous slides#
11.1.1. sumit as per last lecture#
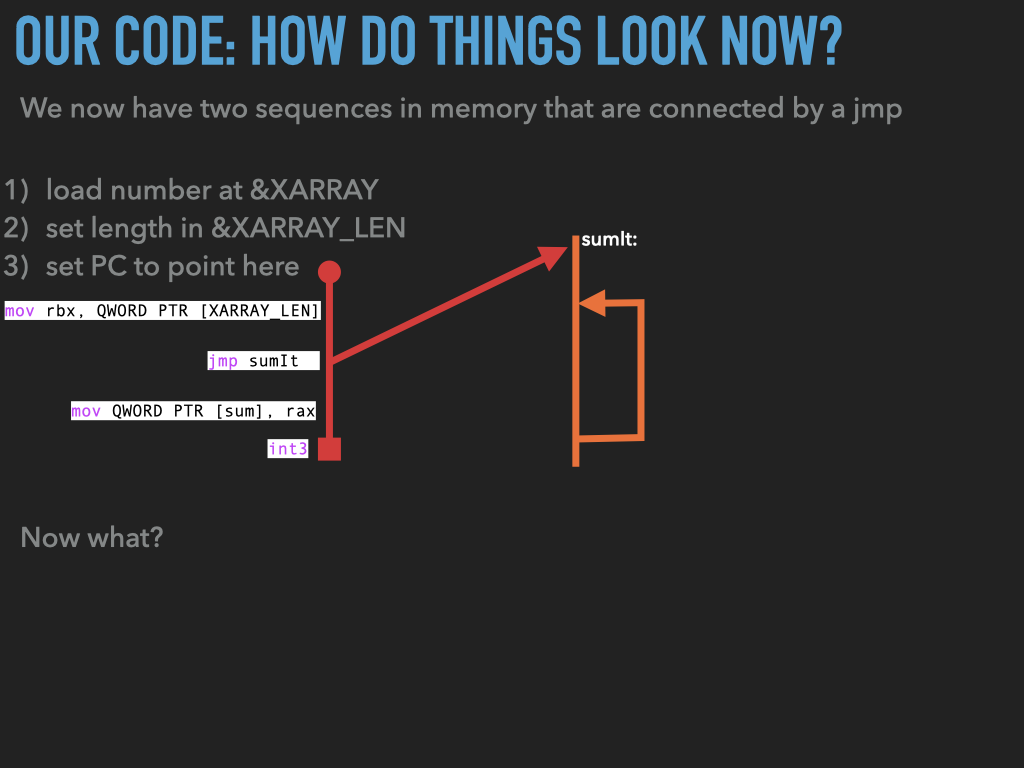
Hardcode int3 stops us from saving our sum as we would like
CODE: asm - sumit.s : Version 1
.intel_syntax noprefix
.section .text
# tell linker that sumIt symbol can be referenced in other files
.global sumIt
# code to sum data at XARRAY
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
sumIt: # location of this code is
xor rax, rax # rax -> sum : sum = 0
xor rdi, rdi # rax -> i : i = 0
# code to sum data at XARRAY
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
loop_start:
cmp rbx, rdi
jz loop_done
add rax, QWORD PTR [XARRAY + rdi * 8] # add the i'th value to the sum
inc rdi # i=i+1
jmp loop_start
loop_done:
int3
Corresponding: usesum
CODE: asm - sumit.s : Version 1
.intel_syntax noprefix
.section .data
# a place for us to store how much data is in the XARRAY
# initalized it to 0
XARRAY_LEN:
.quad 0x0
# reserve enough space for 1024 8 byte values
# third argument is alignment.... turns out cpu
# cpu is more efficient if things are located at address
# of a particular 'alignment (see intel manual)
.comm XARRAY, 8*1024, 8
.comm sum, 8, 8 # space to store final sum
.section .text
.global _start
_start:
mov rbx, QWORD PTR [XARRAY_LEN]
jmp sumIt
mov QWORD PTR [sum], rax
int3
see last lecture notes to in terms of how to use gdb to run and play with usesum
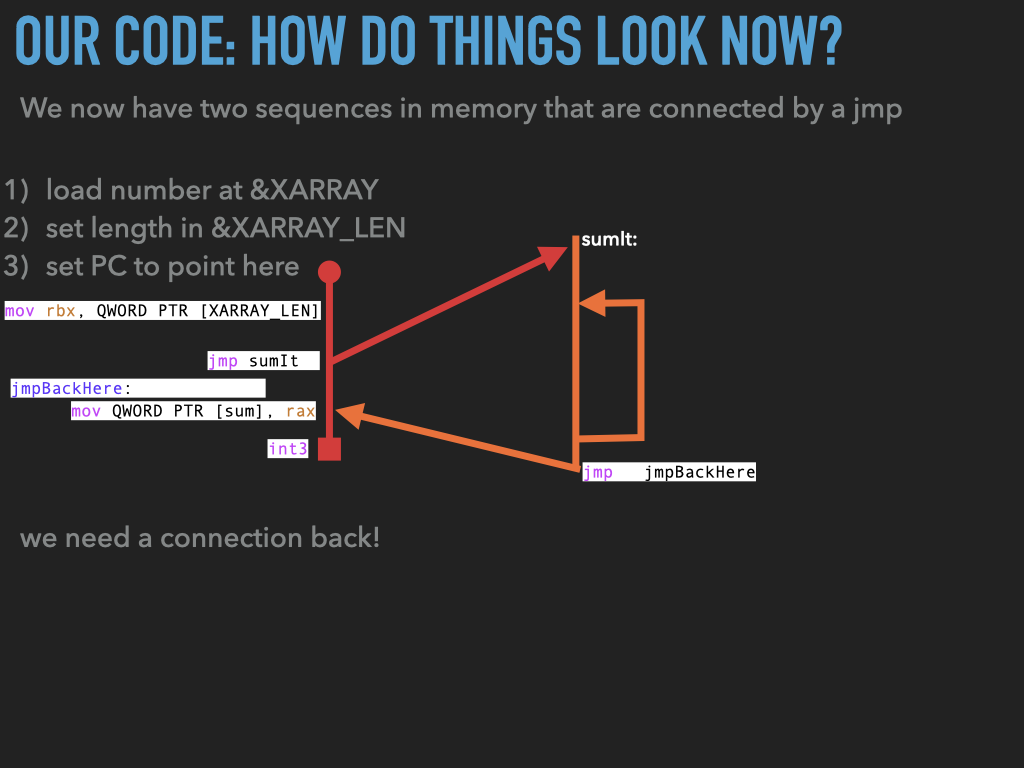
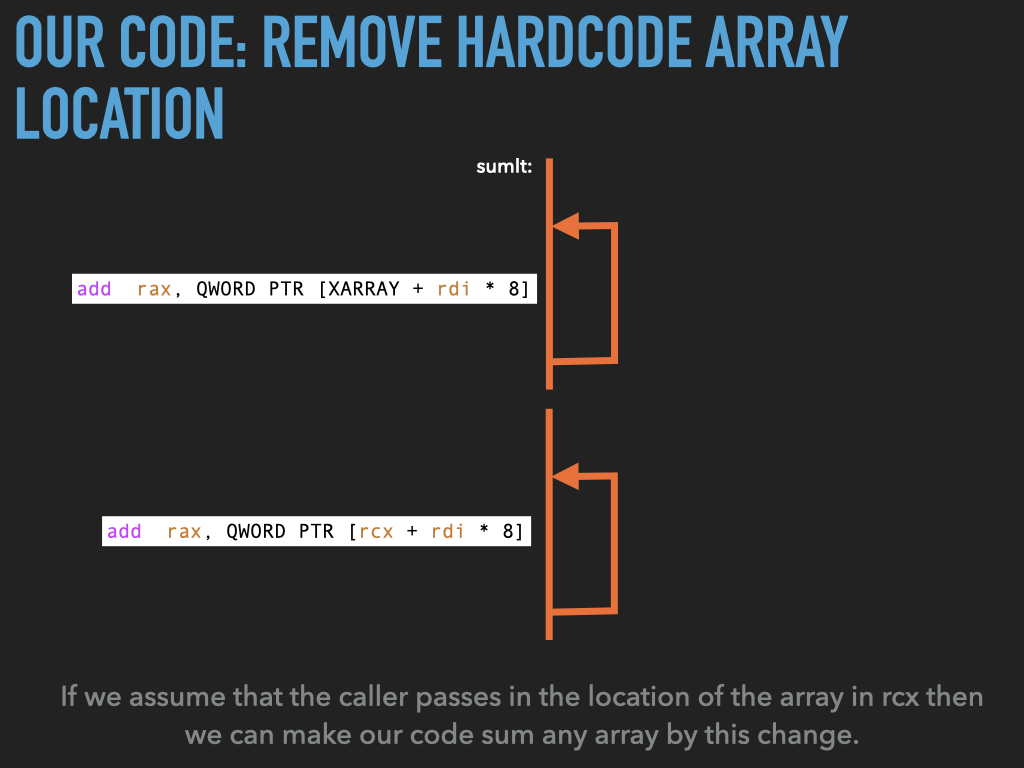
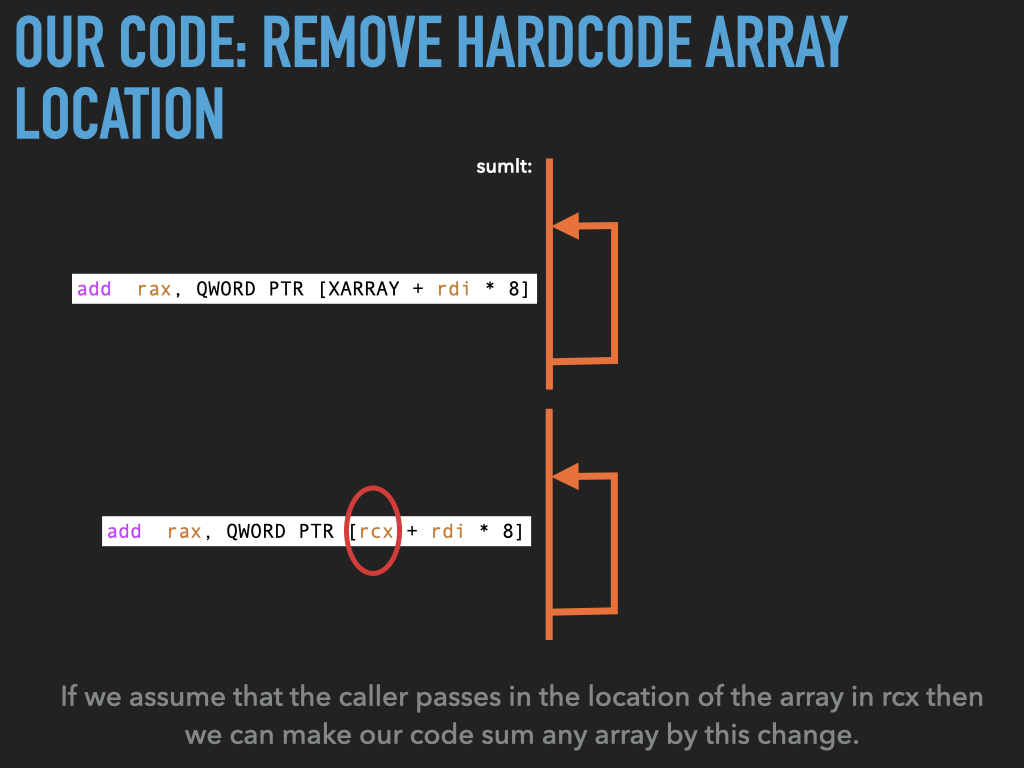
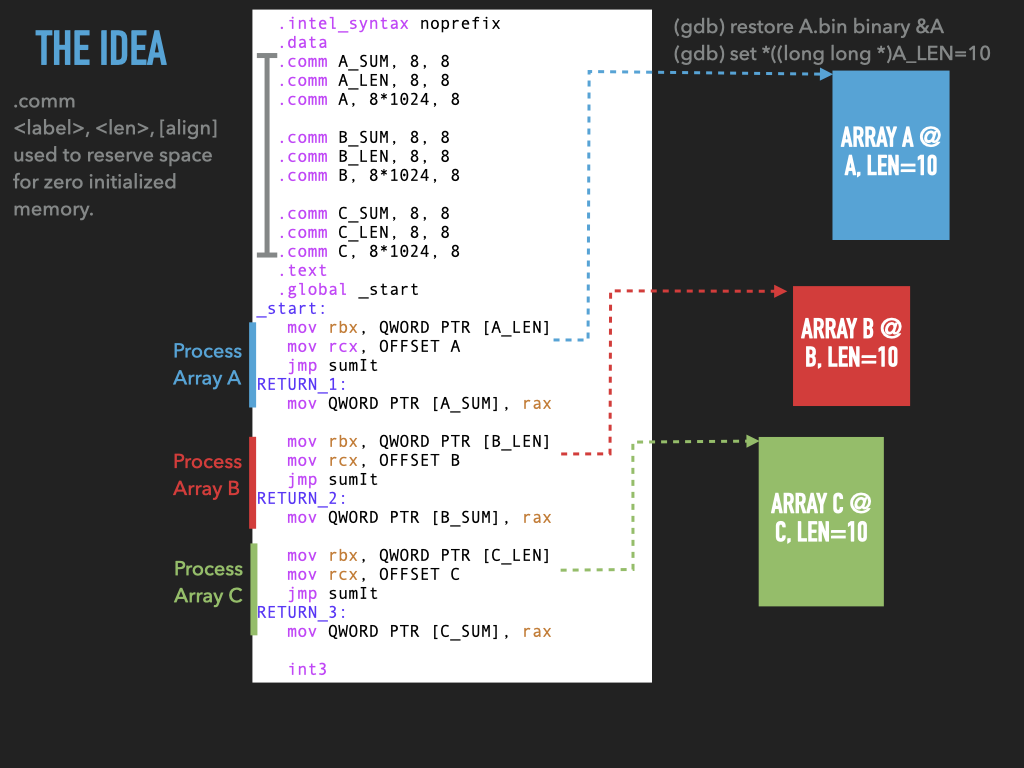
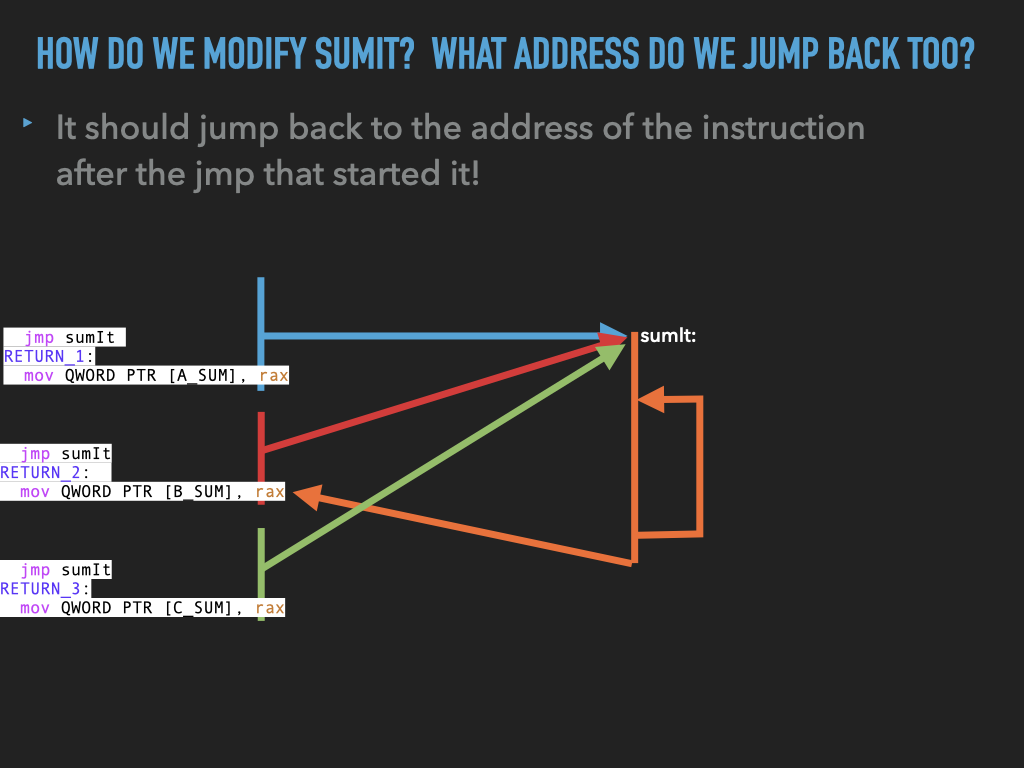
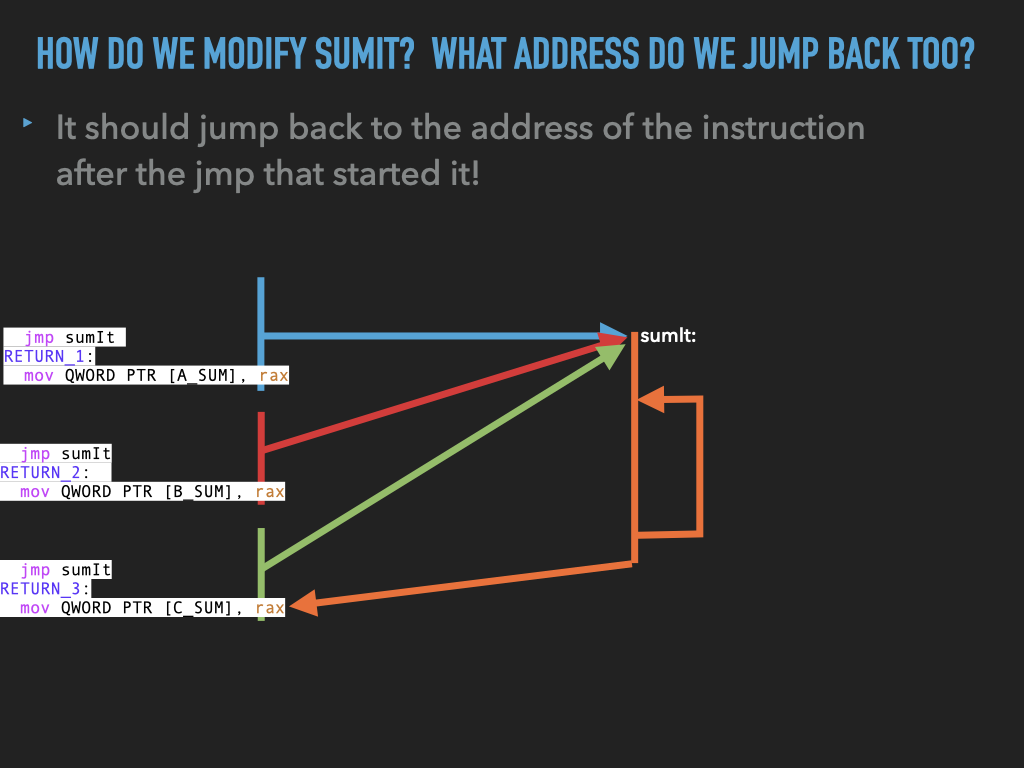
11.1.2. Made sumit more generic but …#
Make the address of the array a parameter passed to
sumit.Changed
sumitcode to use this instead ofXARRAYNow have
usesumleave space for three arrays and have three jumps tosumitremove
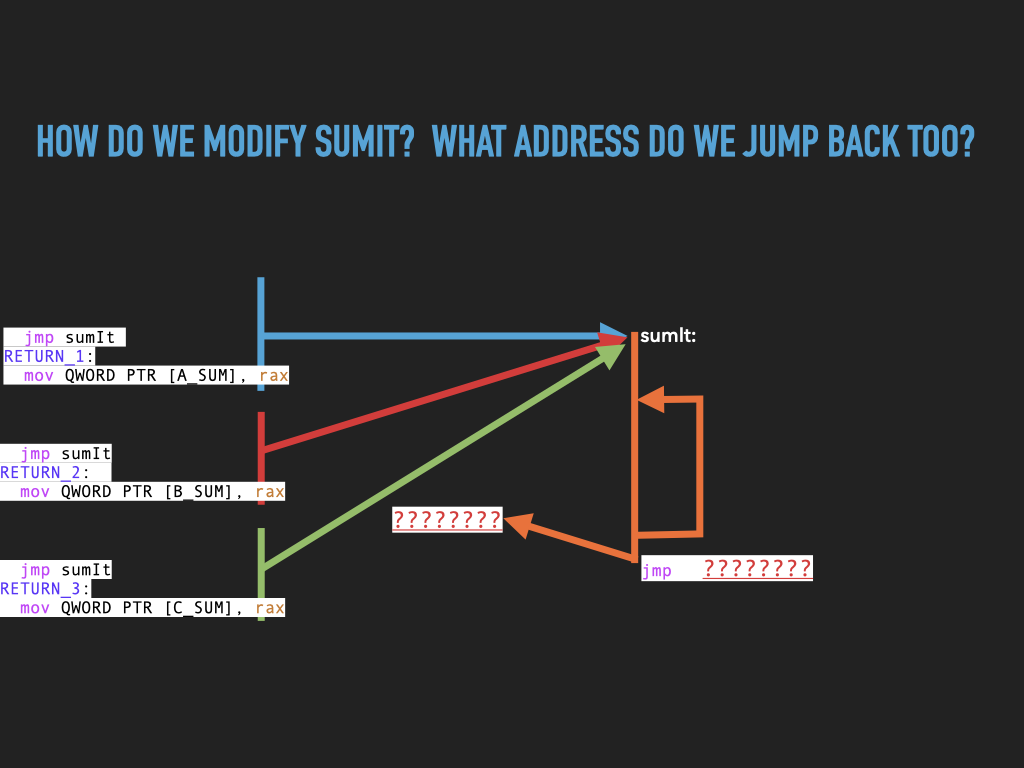
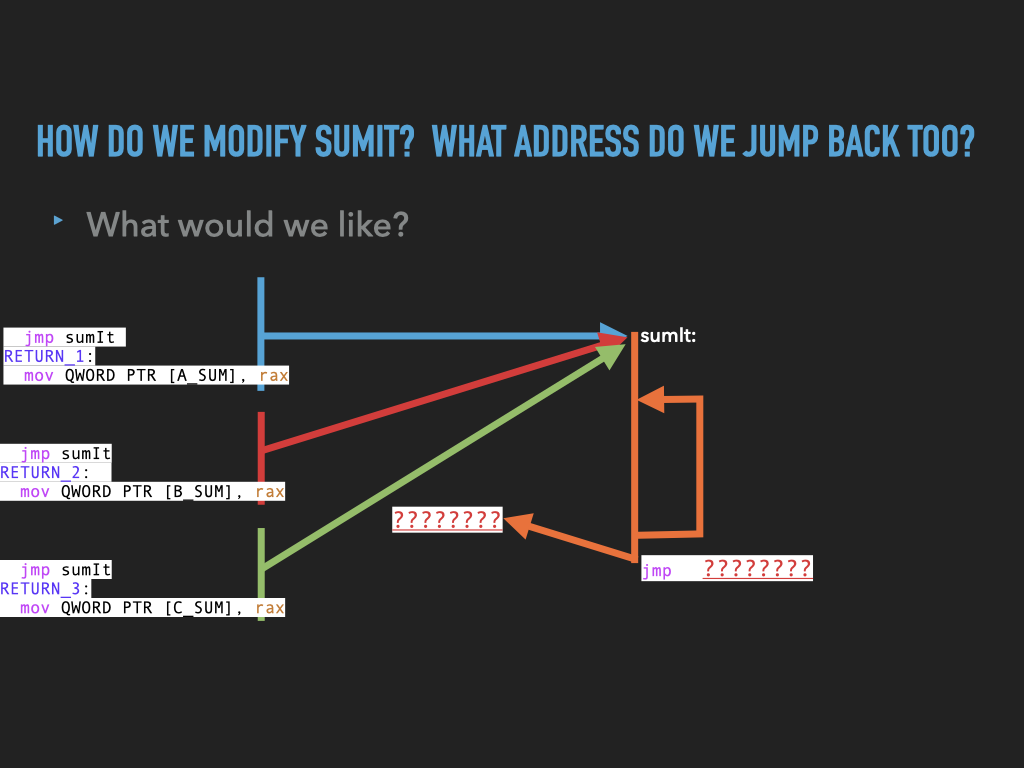
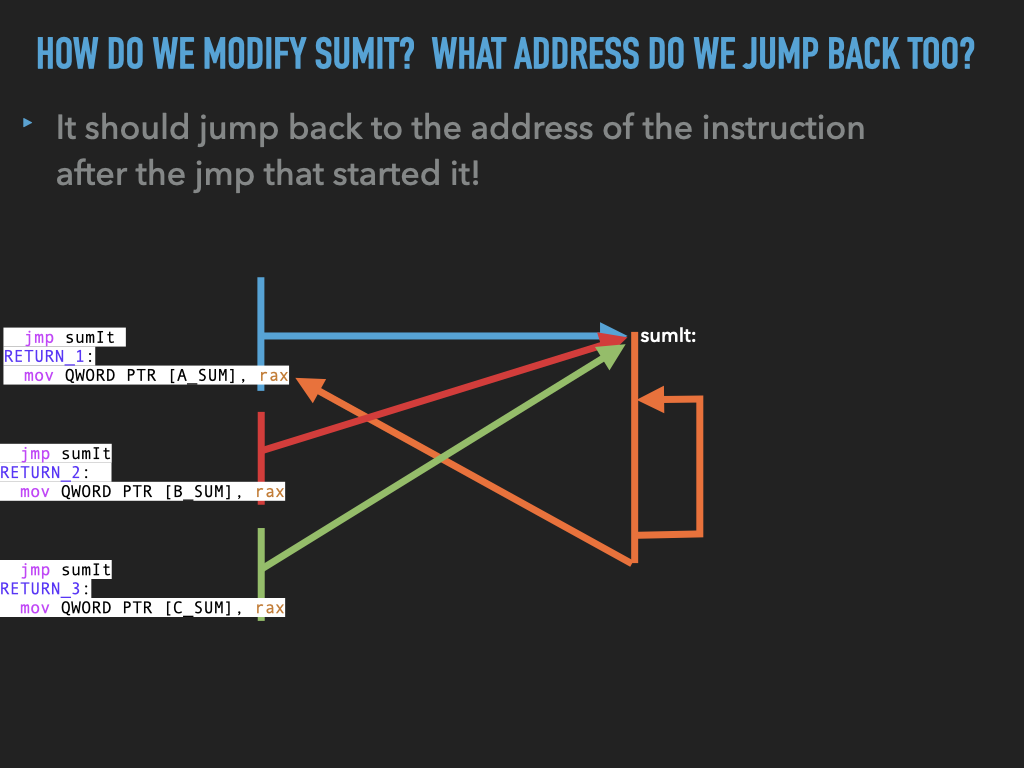
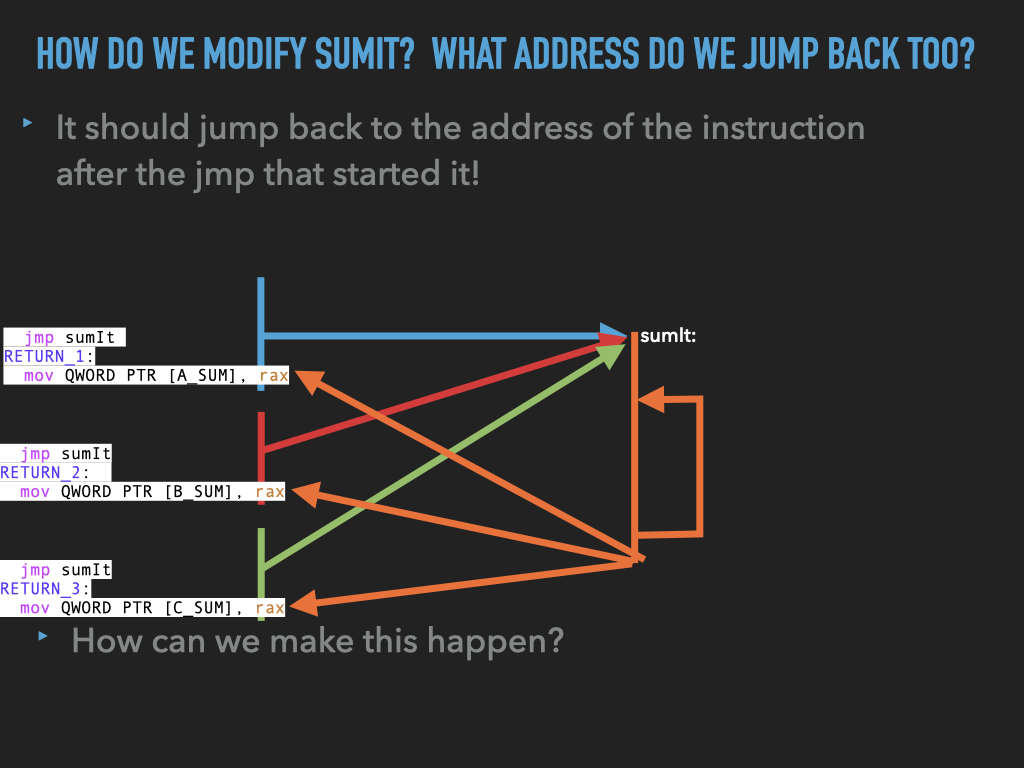
int3fromsumitand replace it with ajmpback to the address after the first jump.BUT WE HAVE PROBLEMS IN
sumit:
how do we
jumpback to the right spot?
CODE: asm - sumit2.s : Version 2
.intel_syntax noprefix
.global sumIt # directive to let the linker
# code to sum data in array who's address is in rcx
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
sumIt: # location of this code is
xor rax, rax # rax -> sum : sum = 0
xor rdi, rdi # rax -> i : i = 0
# code to sum data at value in rcx
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
loop_start:
cmp rbx, rdi
jz loop_done
add rax, QWORD PTR [rcx + rdi * 8] # add the i'th value to the sum
inc rdi # i=i+1
jmp loop_start
loop_done:
jmp RETURN_1
Corresponding: usesum
CODE: asm - usesum2.s : Version 2
.intel_syntax noprefix
.data
.comm A_SUM, 8, 8
.comm A_LEN, 8, 8
.comm A, 8*1024, 8
.comm B_SUM, 8, 8
.comm B_LEN, 8, 8
.comm B, 8*1024, 8
.comm C_SUM, 8, 8
.comm C_LEN, 8, 8
.comm C, 8*1024, 8
.text
.global _start
_start:
mov rbx, QWORD PTR [A_LEN]
mov rcx, OFFSET A
jmp sumIt
RETURN_1:
mov QWORD PTR [A_SUM], rax
mov rbx, QWORD PTR [B_LEN]
mov rcx, OFFSET B
jmp sumIt
RETURN_2:
mov QWORD PTR [B_SUM], rax
mov rbx, QWORD PTR [C_LEN]
mov rcx, OFFSET C
jmp sumIt
RETURN_3:
mov QWORD PTR [C_SUM], rax
int3
.global RETURN_1
.global RETURN_2
.global RETURN_3
GDB commands to use
b _start
run
restore A.bin binary &A
set *((long long *)&A_LEN)=10
restore B.bin binary &B
set *((long long *)&B_LEN)=10
restore C.bin binary &C
set *((long long *)&C_LEN)=10
display /d { (long long)A_SUM, (long long)B_SUM, (long long)C_SUM }
Now you can single step or continue as you like
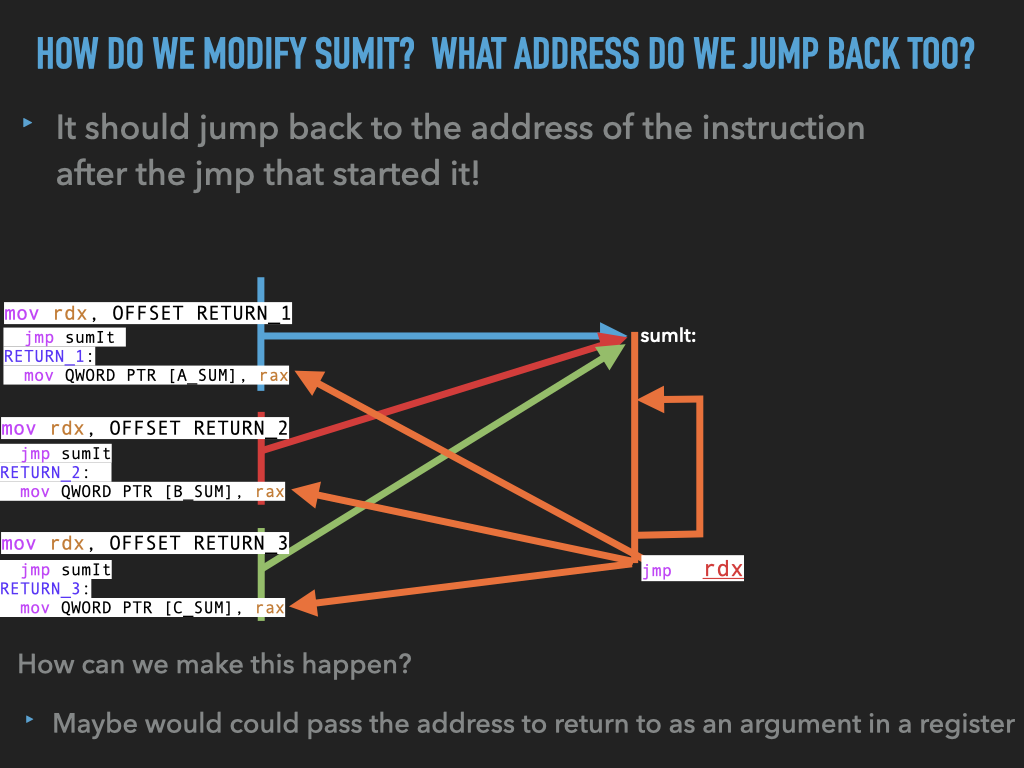
11.1.3. Version 3: Fix our problem by passing in the return address in a register. In our case we use ‘rdx’ and jump back via this register.#
Note this approach requires one register for each call to hold the return address. This has problems if we were to nest calls.
CODE: asm - sumit3.s : Version 3
.intel_syntax noprefix
.global sumIt # directive to let the linker
# code to sum data in array who's address is in rcx
# we assume rdx has the address to jump back too
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
sumIt: # location of this code is
xor rax, rax # rax -> sum : sum = 0
xor rdi, rdi # rax -> i : i = 0
# code to sum data at value in rcx
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
loop_start:
cmp rbx, rdi
jz loop_done
add rax, QWORD PTR [rcx + rdi * 8] # add the i'th value to the sum
inc rdi # i=i+1
jmp loop_start
loop_done:
jmp rdx
Corresponding: usesum
CODE: asm - usesum3.s : Version 3
.intel_syntax noprefix
.data
.comm A_SUM, 8, 8
.comm A_LEN, 8, 8
.comm A, 8*1024, 8
.comm B_SUM, 8, 8
.comm B_LEN, 8, 8
.comm B, 8*1024, 8
.comm C_SUM, 8, 8
.comm C_LEN, 8, 8
.comm C, 8*1024, 8
.text
.global _start
_start:
mov rbx, QWORD PTR [A_LEN]
mov rcx, OFFSET A
mov rdx, OFFSET RETURN_1
jmp sumIt
RETURN_1:
mov QWORD PTR [A_SUM], rax
mov rbx, QWORD PTR [B_LEN]
mov rcx, OFFSET B
mov rdx, OFFSET RETURN_2
jmp sumIt
RETURN_2:
mov QWORD PTR [B_SUM], rax
mov rbx, QWORD PTR [C_LEN]
mov rcx, OFFSET C
mov rdx, OFFSET RETURN_3
jmp sumIt
RETURN_3:
mov QWORD PTR [C_SUM], rax
int3
.global RETURN_1
.global RETURN_2
.global RETURN_3
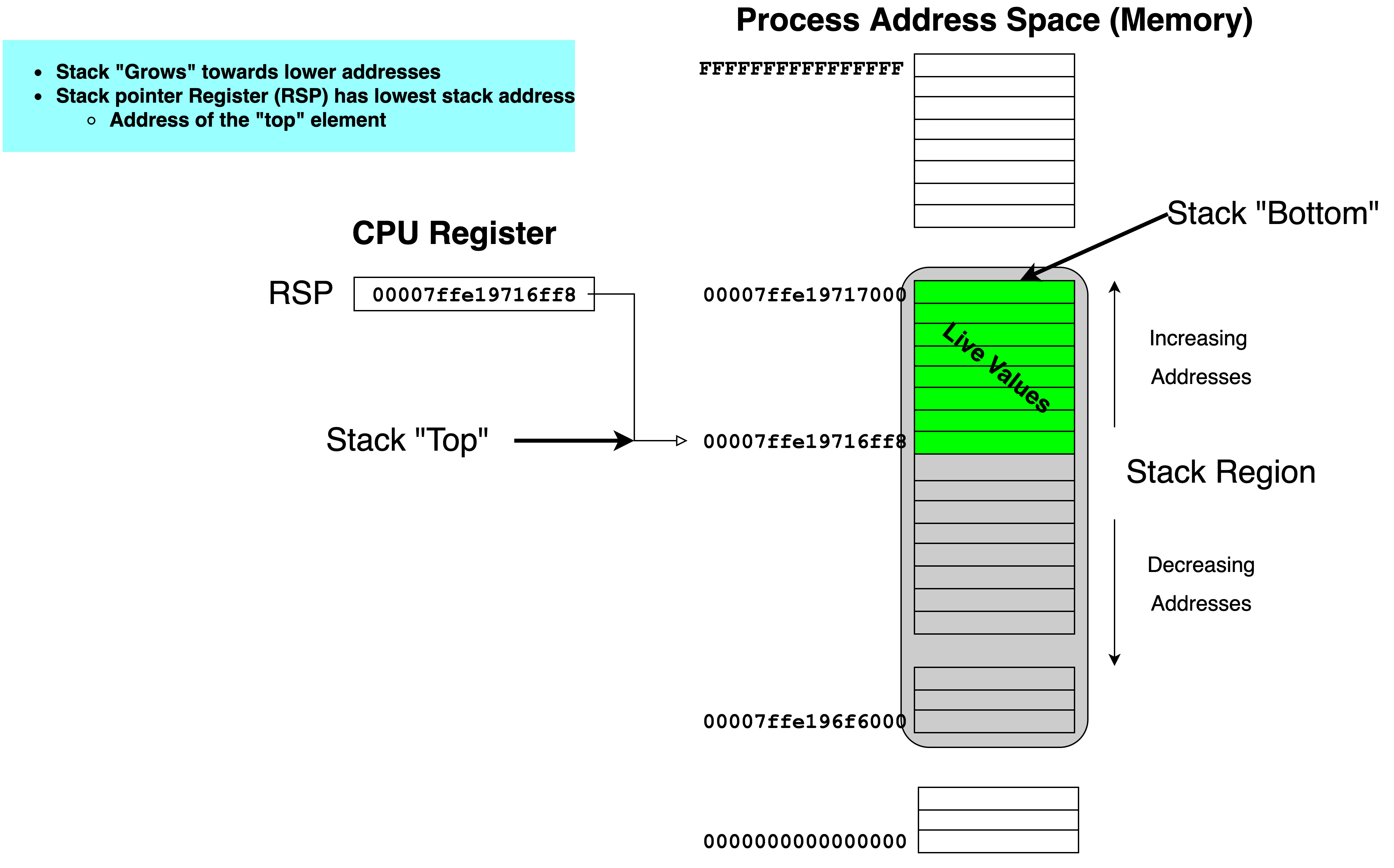
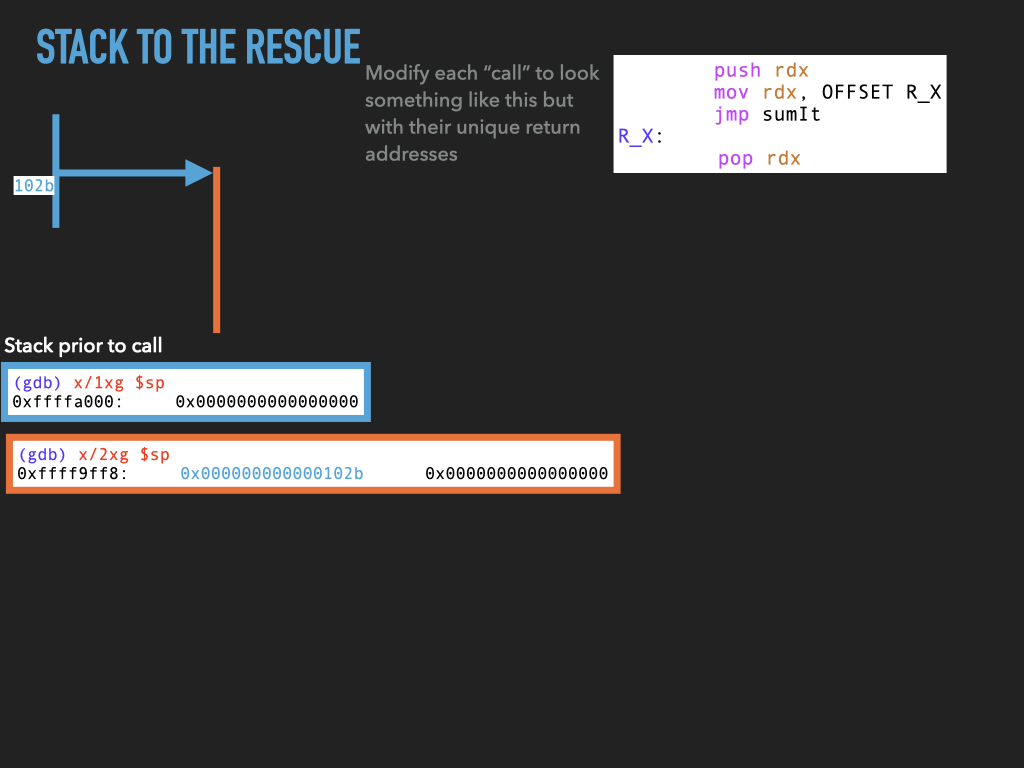
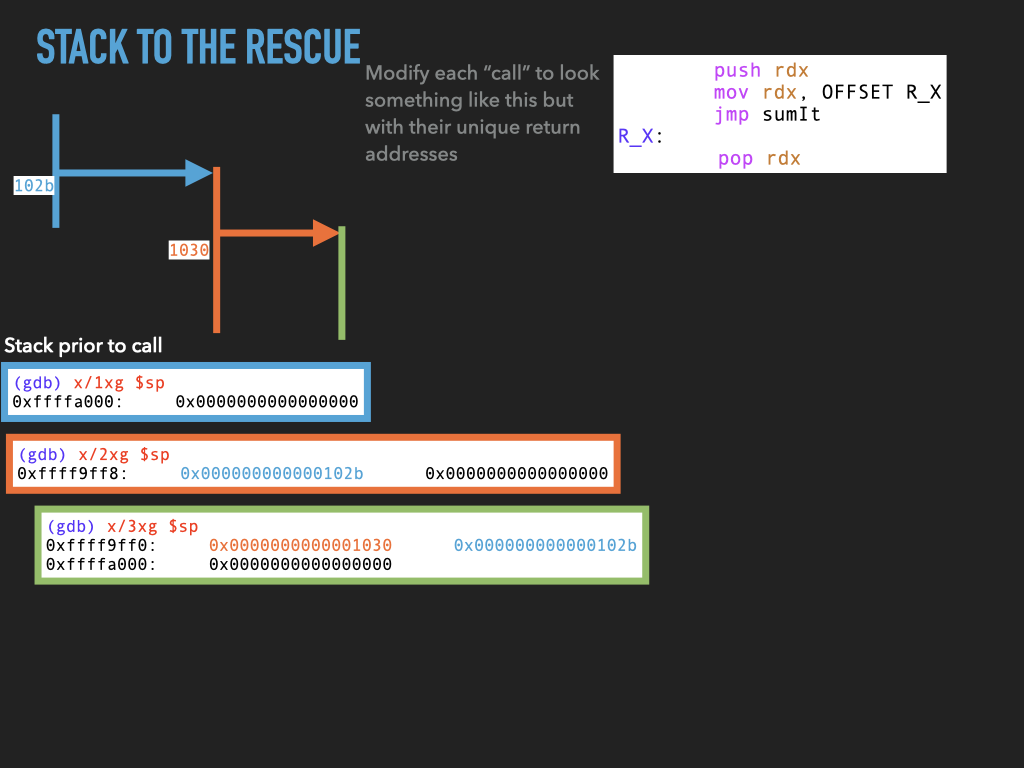
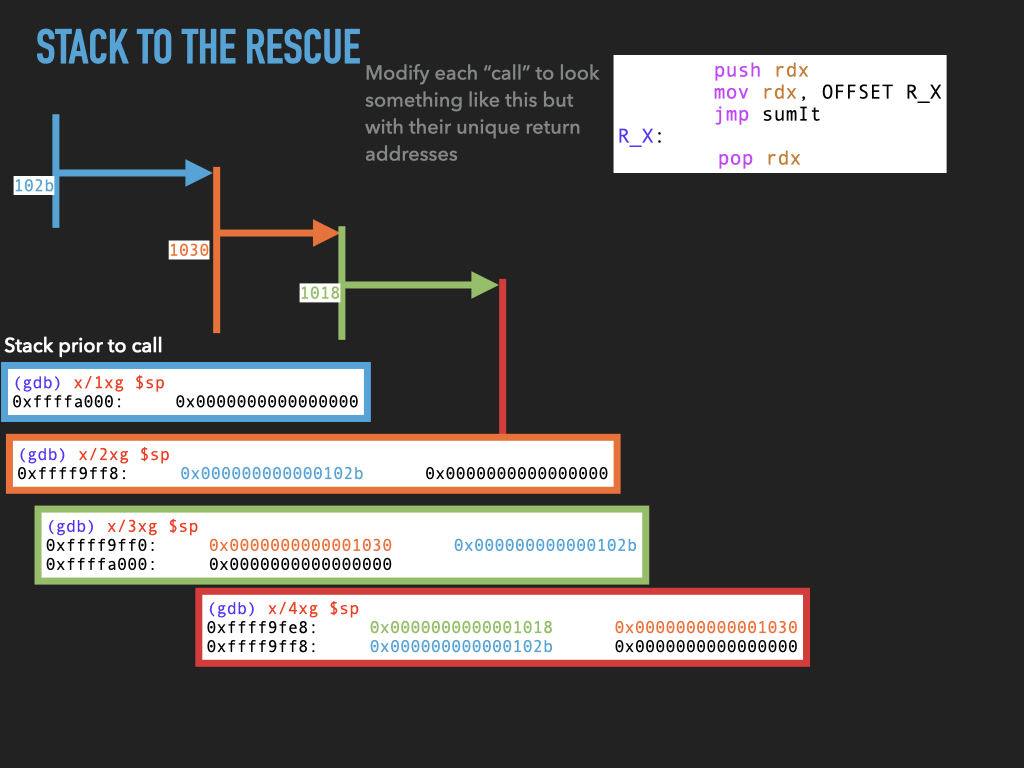
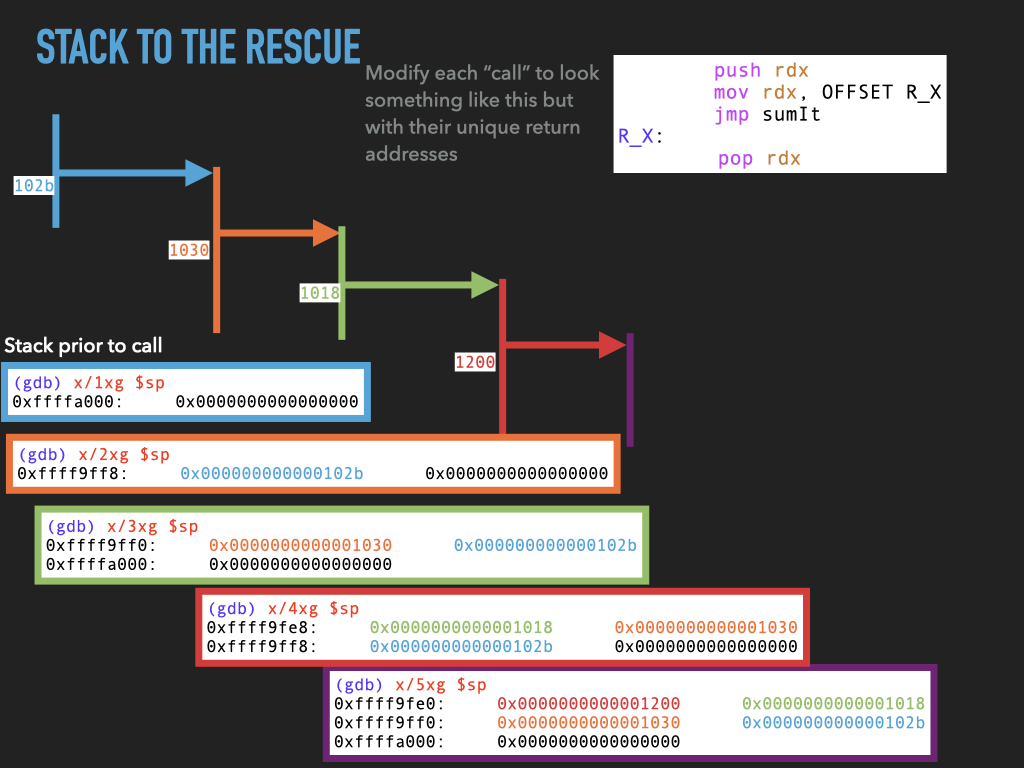
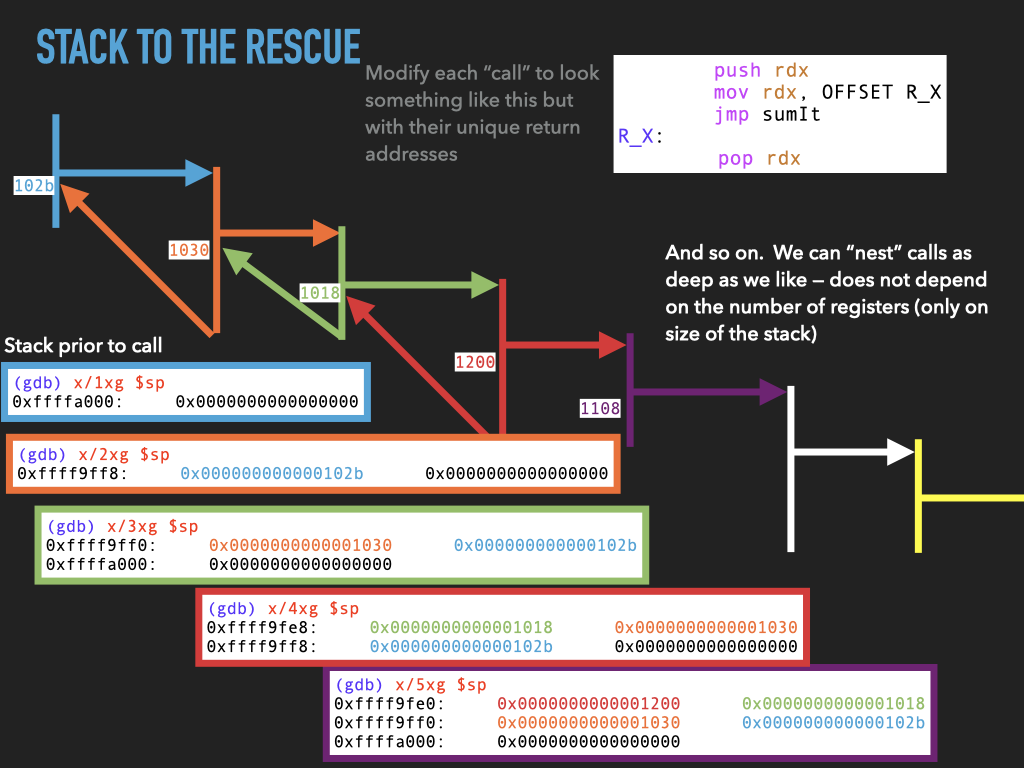
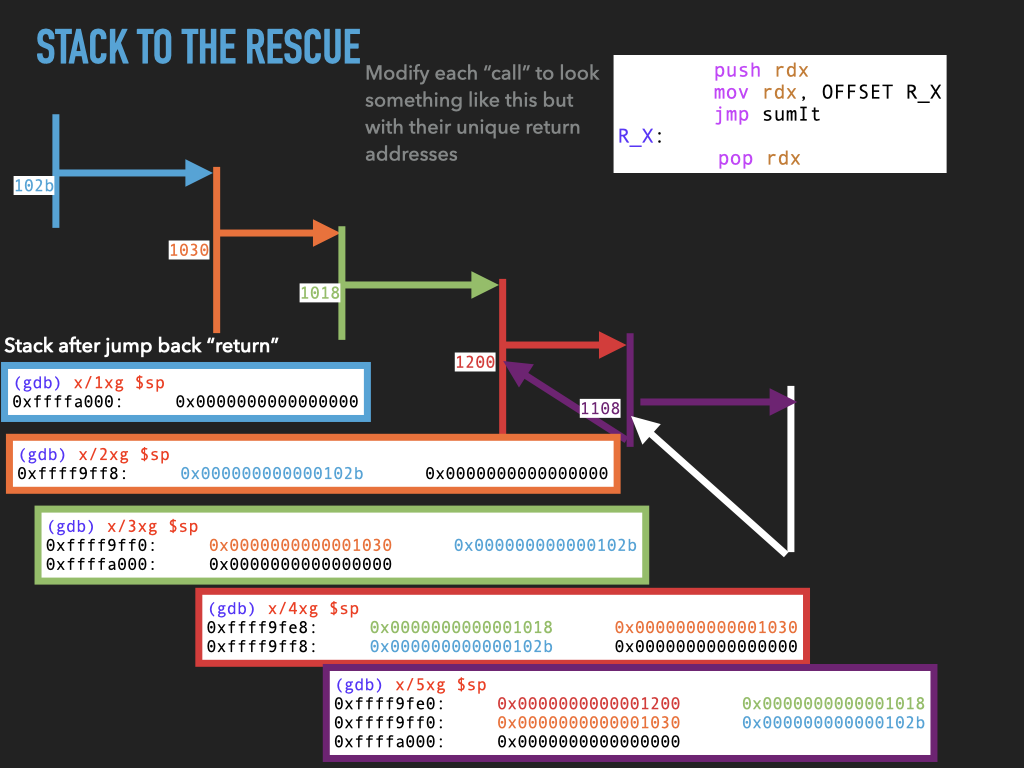
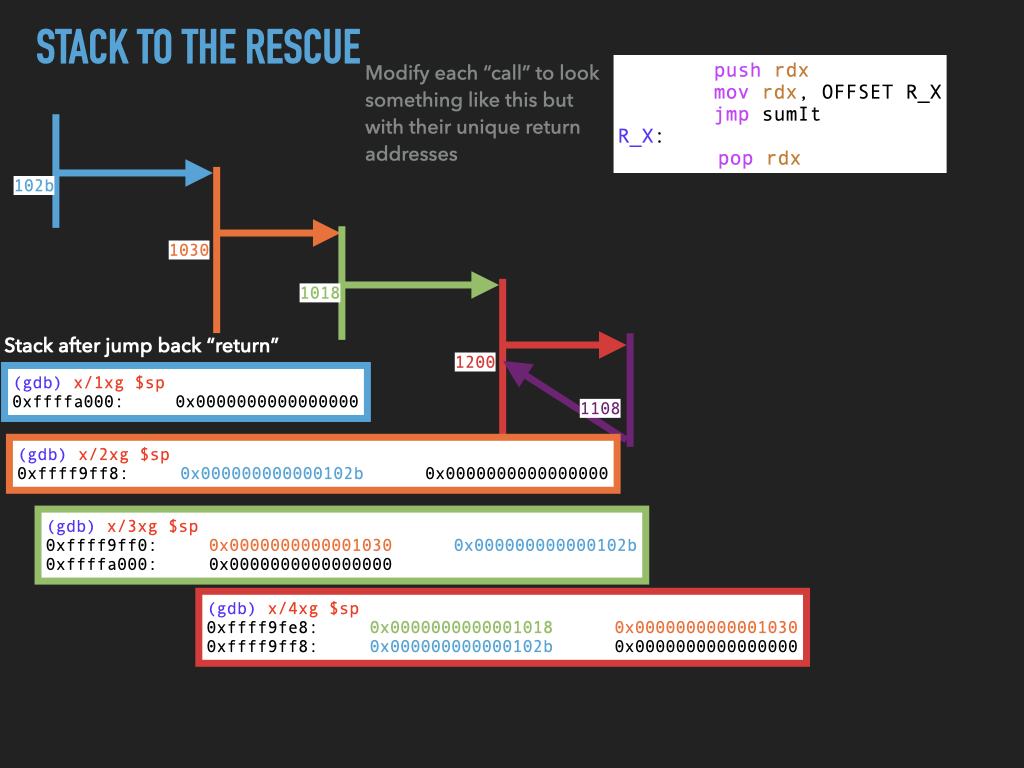
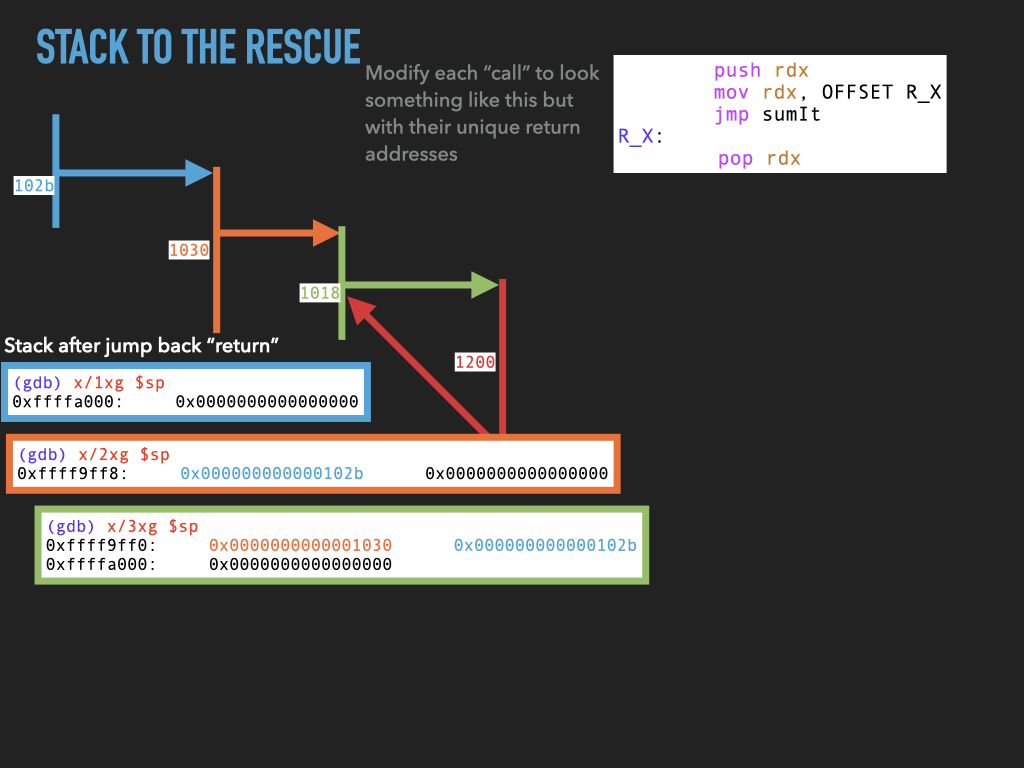
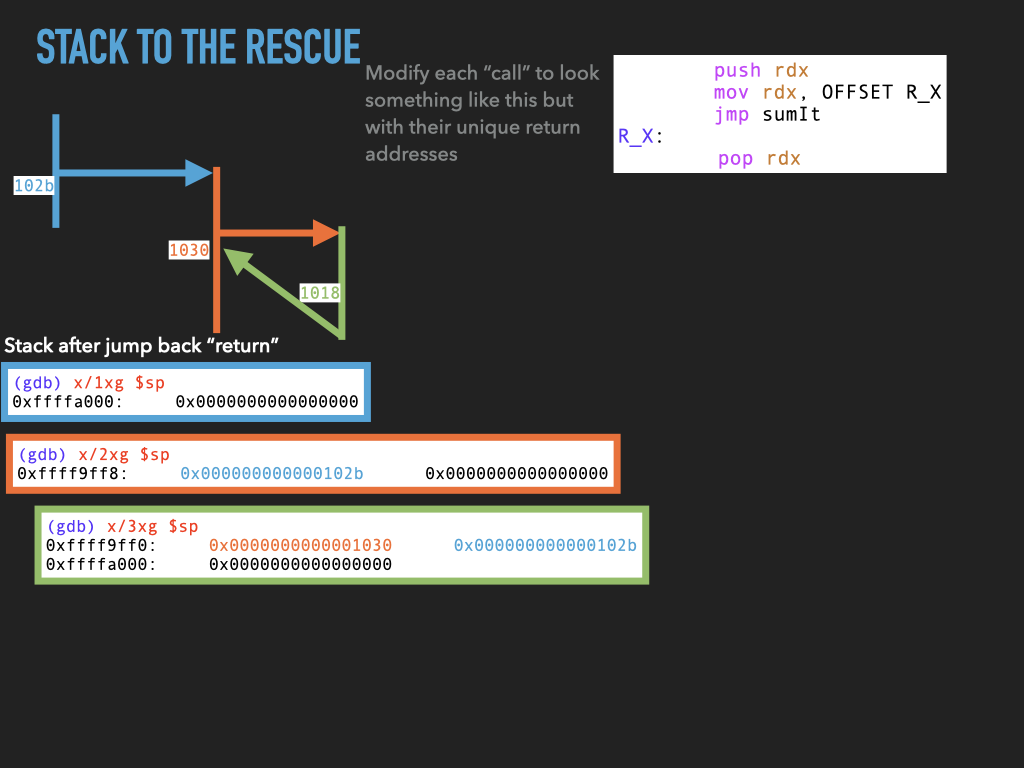
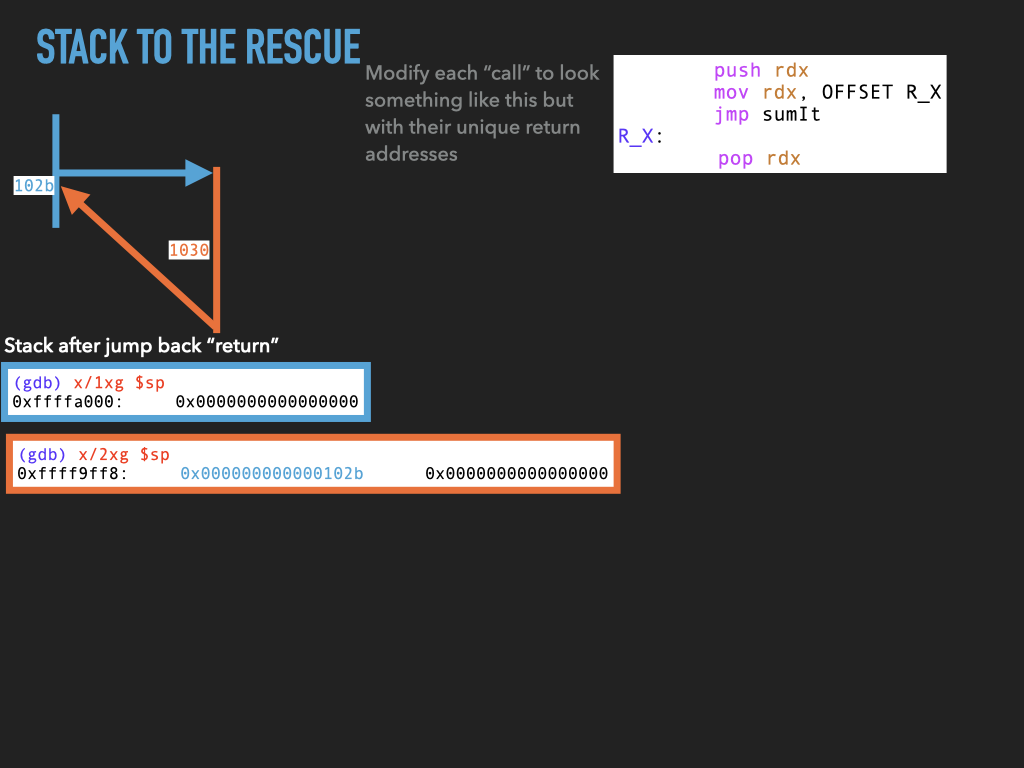
11.1.4. Version 4: Use stack to spill rdx before making any call.#
Although we don’t use it this would allow us to make nested calls assuming we always used the same register to pass the return address in. In our case rdx. This approach effectively uses the stack to spill rdx before we use it to make a call. In this way the caller is using the stack to hang on to where it needs to return before making a new call.
CODE: asm - sumit3.s : Version 4 no change use version 3
.intel_syntax noprefix
.global sumIt # directive to let the linker
# code to sum data in array who's address is in rcx
# we assume rdx has the address to jump back too
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
sumIt: # location of this code is
xor rax, rax # rax -> sum : sum = 0
xor rdi, rdi # rax -> i : i = 0
# code to sum data at value in rcx
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
loop_start:
cmp rbx, rdi
jz loop_done
add rax, QWORD PTR [rcx + rdi * 8] # add the i'th value to the sum
inc rdi # i=i+1
jmp loop_start
loop_done:
jmp rdx
Corresponding: usesum
CODE: asm - usesum4.s : Version 4
.intel_syntax noprefix
.data
.comm A_SUM, 8, 8
.comm A_LEN, 8, 8
.comm A, 8*1024, 8
.comm B_SUM, 8, 8
.comm B_LEN, 8, 8
.comm B, 8*1024, 8
.comm C_SUM, 8, 8
.comm C_LEN, 8, 8
.comm C, 8*1024, 8
.text
.global _start
_start:
mov rbx, QWORD PTR [A_LEN]
mov rcx, OFFSET A
push rdx
mov rdx, OFFSET RETURN_1
jmp sumIt
RETURN_1:
pop rdx
mov QWORD PTR [A_SUM], rax
mov rbx, QWORD PTR [B_LEN]
mov rcx, OFFSET B
push rdx
mov rdx, OFFSET RETURN_2
jmp sumIt
RETURN_2:
pop rdx
mov QWORD PTR [B_SUM], rax
mov rbx, QWORD PTR [C_LEN]
mov rcx, OFFSET C
push rdx
mov rdx, OFFSET RETURN_3
jmp sumIt
RETURN_3:
pop rdx
mov QWORD PTR [C_SUM], rax
int3
.global RETURN_1
.global RETURN_2
.global RETURN_3
11.1.5. Version 5: Use call and ret instructions to turn our code into an “real” X86 function#
CODE: asm - sumit5.s : Version 5
.intel_syntax noprefix
.global sumIt # directive to let the linker
# code to sum data in array who's address is in rcx
# we assume we were started with call so return address on stack
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
sumIt: # location of this code is
xor rax, rax # rax -> sum : sum = 0
xor rdi, rdi # rax -> i : i = 0
# code to sum data at value in rcx
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
loop_start:
cmp rbx, rdi
jz loop_done
add rax, QWORD PTR [rcx + rdi * 8] # add the i'th value to the sum
inc rdi # i=i+1
jmp loop_start
loop_done:
ret
Corresponding: usesum
CODE: asm - usesum5.s : Version 5
.intel_syntax noprefix
.data
.comm A_SUM, 8, 8
.comm A_LEN, 8, 8
.comm A, 8*1024, 8
.comm B_SUM, 8, 8
.comm B_LEN, 8, 8
.comm B, 8*1024, 8
.comm C_SUM, 8, 8
.comm C_LEN, 8, 8
.comm C, 8*1024, 8
.text
.global _start
_start:
mov rbx, QWORD PTR [A_LEN]
mov rcx, OFFSET A
call sumIt
mov QWORD PTR [A_SUM], rax
mov rbx, QWORD PTR [B_LEN]
mov rcx, OFFSET B
call sumIt
mov QWORD PTR [B_SUM], rax
mov rbx, QWORD PTR [C_LEN]
mov rcx, OFFSET C
call sumIt
mov QWORD PTR [C_SUM], rax
int3
11.1.6. Version 6 improving code by “spilling” rdi in sumIt#
CODE: asm - sumit6.s : Version 6
.intel_syntax noprefix
.global sumIt # directive to let the linker
# code to sum data in array who's address is in rcx
# we assume we were started with call so return address on stack
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
sumIt: # location of this code is
xor rax, rax # rax -> sum : sum = 0
push rdi # spill current value of rdi before we use
xor rdi, rdi # rax -> i : i = 0
# code to sum data at value in rcx
# we assume rbx has length rbx -> len
# and that we will leave final sum in rax
loop_start:
cmp rbx, rdi
jz loop_done
add rax, QWORD PTR [rcx + rdi * 8] # add the i'th value to the sum
inc rdi # i=i+1
jmp loop_start
loop_done:
pop rdi # restore rdi back to its original value
ret
Corresponding: usesum
CODE: asm - usesum5.s : Version 6 no change to usesum use Version 5
.intel_syntax noprefix
.data
.comm A_SUM, 8, 8
.comm A_LEN, 8, 8
.comm A, 8*1024, 8
.comm B_SUM, 8, 8
.comm B_LEN, 8, 8
.comm B, 8*1024, 8
.comm C_SUM, 8, 8
.comm C_LEN, 8, 8
.comm C, 8*1024, 8
.text
.global _start
_start:
mov rbx, QWORD PTR [A_LEN]
mov rcx, OFFSET A
call sumIt
mov QWORD PTR [A_SUM], rax
mov rbx, QWORD PTR [B_LEN]
mov rcx, OFFSET B
call sumIt
mov QWORD PTR [B_SUM], rax
mov rbx, QWORD PTR [C_LEN]
mov rcx, OFFSET C
call sumIt
mov QWORD PTR [C_SUM], rax
int3